


All great changes are preceded by chaos.
-Deepak Chopra.
Software resilience is the ability of software to recover from unexpected events. It\’s an essential quality of any software that is scalable, performant, and fault-tolerant.
This means that a software engineer has to anticipate unexpected events and account for them.
When you are architecting a solution, resilience is vital, but really hard to achieve, especially in distributed systems. Every time you add a new component you are introducing a lot of variables that can affect the behaviour of your application.
Simple things like adding a database could lead to multiple problems. For example:
- What happens if the server your database is running on goes down? Your application might be up but some functionality might not work.
- How do you guarantee your application will continue to run? Possibly by having a backup connection.
- What happens if your database is running but one of your application servers goes down and you are not able to manage the traffic? Don’t worry, this happens all the time!
This article outlines the basic concepts for you to understand a little bit more about resilience and how to avoid chaos in your systems.
Introduction
Before we delve in to this subject, let’s take a quick look at the key terms:
Scalability is the measure of a system\’s ability to increase, or decrease, in performance and cost in response to changes in application and system processing demands.
Chaos engineering is the process of testing a distributed computing system to ensure that it can withstand unexpected disruptions. It relies on concepts underlying the chaos theory, which focus on random and unpredictable behaviour.
Disaster recovery is an organisation\’s method of regaining access and functionality to its IT infrastructure following unpredictable events like natural disaster, cyber attack, or even business disruptions. A variety of disaster recovery (DR) methods can be part of a disaster recovery plan.
It is very common to come across these terms – but what do they mean, and how are they related?
Scalability
Scalability is probably one of the easiest concepts to understand; the system needs to be able to increase its capacity to attend to certain workloads, but also decrease it in order to reduce cost (which is really important).
Vertical and Horizontal scalability
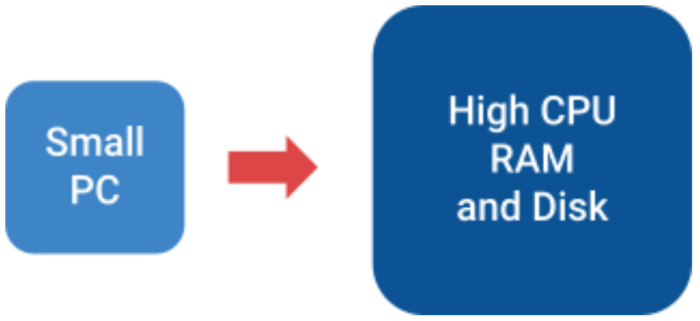
You can think of vertical scalability as increasing your current computer capabilities.
Let’s say you are planning to run a new game on your computer and you need specific RAM or CPU, by increasing those components you are achieving vertical scalability.
Now if we think about horizontal scalability is quite different, let’s suppose you would like to play a multiplayer game with some friends, and you will need different computers in order to meet the demand, by supplying different computers you will be achieving horizontal scalability.
Vertical
Horizontal

And this example can easily be translated to other scenarios. For example, if your database needs to process a lot of read/write operations in a short period of time, you might want to upgrade the Disk or the CPU your system is running on. However, if you just need to perform multiple reads, it might be better to use read replicas from where your users will be able to read the data, and just have a single instance to do the write operations.
Another example if we talk about scaling our applications, is the use of load balancers to manage traffic and use auto scaling groups in the cloud. Alternatively, many of us rely on Kubernetes’ capabilities, but you will still have the underlying infrastructure you’ll need to manage to support scalability. There are tools like AWS Fargate that would handle that for you, or if you are coding a Serverless application you might not need to think about all this mess, but if not, you will need to deal with AutoScalling groups, read/write capacity planning, etc. You will need to answer questions like would this amount of machines be enough to manage the load? And most importantly, how much will we spend if we scale and we don’t use it?
Understanding chaos engineering
A chaos engineering tool implements a perturbation model. The perturbations, also called turbulences, are meant to mimic rare or catastrophic events that can happen in production.
To maximize the added value of chaos engineering, the perturbations are expected to be realistic.
Server shutdowns. One perturbation model consists of randomly shutting down servers. Netflix\’ Chaos Monkey is an implementation of this perturbation model.
Latency injection. Introduces communication delays to simulate degradation or outages in a network. For example, Chaos Mesh supports the injection of latency.
Resource exhaustion. Eats up a given resource. For instance, Gremlin can fill the disk up.
In order to understand how to perform chaos engineering to test your systems, you’ll need to follow these steps:
- Build a Hypothesis around Steady State Behaviour
- Vary Real-world Events
- Run Experiments in Production
- Automate Experiments to Run Continuously
- Minimise Blast Radius
Once you have a set of hypotheses and plans, you can go ahead and run the simulations. Keep in mind that in order to get real results, most companies try these things in a production environment, without letting anyone know. By doing this, you are not only able to test how your infrastructure responds to chaos, but you can also test how effectively your team reacts.
Some tools you can use if you want to test your systems using chaos engineering are:
- Gremlin is the first hosted Chaos Engineering service designed to improve web-based reliability. Offered as a SaaS (Software-as-a-Service) technology, Gremlin is able to test system resiliency using one of three attack modes. https://www.gremlin.com/
- Litmus is an open-source Chaos Engineering platform designed for cloud-native infrastructures and applications. It assists teams with identifying system deficiencies and outages by performing controlled chaos tests. Litmus uses a cloud-native strategy to closely control and manage chaos. https://litmuschaos.io/
- Chaos Monkey randomly terminates virtual machine instances and containers that run inside of your production environment. Exposing engineers to failures more frequently incentivizes them to build resilient services. https://github.com/Netflix/chaosmonkey
- There is another good thing you can use if you are more familiar with AWS, you can follow up this article on how to implement chaos engineering using Fault Injector Simulator and Code-Pipeline. https://aws.amazon.com/blogs/architecture/chaos-testing-with-aws-fault-injection-simulator-and-aws-codepipeline/
Disaster recovery strategies
To understand disaster recovery we need to understand two main concepts:
Recovery Point Objective (RPO) describes the maximum acceptable amount of time since the last data recovery point. It can be thought of as the time between the time of data loss and the last useful backup of a known good state (how frequently you take backups).
Recovery Time Objective (RTO) is the duration of time or the service level within which a business process must be restored after a disaster, in order to avoid consequences associated with a break in continuity. In other words, the RTO is the answer to the question: “How much time did it take to recover after we got notified about a business process disruption?“
There are a variety of strategies many companies have, but there are always similarities or patterns they all follow around disaster recovery events. Some of the most common strategies are:
- Backup and Restore: you backup and restore your servers, either with backups you already have or you just created. This might have a huge Recovery Time Objective.
- Pilot light: you have a small version of your app running. Usually this version will just have the critical functionality, so in case of emergency you can immediately redirect the traffic from your main application to the light version which you can then scale adding the missing functionality.
- Warm Standby: your full application is running on a minimal scale. In case of emergency you allocate the traffic and scale up.
- Hot Site: your full application is running at full scale, you just redirect traffic to your backup application achieving 100% availability.
Of course, as with everything in engineering, there are always pros and cons. As you can see, having a minimal RTO and RPO might represent a bigger cost. Before implementing any of these patterns, you should analyse which one is the fastest and most cost effective according to your company needs.
How do all the pieces work together?
If you are architecting an application you might already be thinking about these different things.
A rule of thumb or a checklist you should always have in mind is:
- You need to be thinking on building resilient applications
- Your application needs to be scalable
- You need to have disaster recovery plans
- Test your system against failures
- Evaluate results, adjust, review this list again 🙂
Having a resilient distributed application is not something that you will easily achieve. Imagine that companies like Netflix are constantly adjusting and testing, over and over again. Arm yourself with patience and get comfortable with the chaos!